
Addressing Big Data analytics with SQL Server 2012: Q & A with chief Yellowfin architect, Peter Damen
What do Microsoft and Yellowfin have in common? Stumped? It’s ok. It’s Friday. I’ll just give you the answer.
The latest release of Yellowfin’s Business Intelligence (BI) software (Yellowfin 6.1), had a large focus on equipping organizations with the support required to realize their Big Data analytics initiatives, offering support for a greater range of databases including D3, Connection Cloud, Lucid, Greenplum, Hadoop, SAP Hana, Vertica and SAS dataset connection.
Microsoft’s latest iteration of its relational database application, SQL Server 2012, did the same.
SQL Server 2012 incorporates a number of enhancements specifically designed to improve BI performance and stability for organizations analyzing Big Data. New additions include complete fault tolerance and disaster recovery with its ‘AlwaysOn’ feature, as well as significant performance improvements for analytics and data warehousing (of 10x – 100x) with its new ‘xVelocity’ in-memory technologies, which allows users to explore unprecedented amounts of data in real-time.

Microsoft’s whitepaper on SQL Server 2012, Solution Overview – Breakthrough Insight, also stated that the database provides support for “massive data warehousing”, with “enhanced features such as Remote Blob Storage and partitioned tables that scale to 15,000 partitions to support large sliding window scenarios.” Also available is “increased support for up to 256 logical cores to enable high-performance for very large workloads and consolidation scenarios. SQL Server 2012 also activates non-relational data types, bridging beyond the DataWarehouse to embrace Big Data through Hadoop.”
SQL Server 2012, like Yellowfin, enables Big Data exploration with native support for Hadoop – a free open-source Java-based framework from the Apache Software Foundation that supports the distribution and running of applications on clusters of servers with thousands of nodes and petabytes of data.

So, seeing as Yellowfin and SQL Server 2012 are aligned in their respective missions to enable organizations to explore and leverage their proliferating data sources, a partnership seemed only natural.

So, how exactly does Yellowfin 6.1 support SQL Server 2012 – the database codenamed ‘Denali’?
6 questions with chief Yellowfin product architect, Peter Damen
1. Ok, so what is SQL Server 2012?
“SQL Server, developed by Microsoft, is a relational database management system. Its chief function is to store and retrieve data as requested by other software applications. SQL Server 2012 is the latest iteration of Microsoft’s database application.
“There are around a dozen or more different editions of SQL Server 2012, aimed at catering for different workloads. Yellowfin is one of the first Australian ISVs to offer support for all editions of SQL Server 2012.”
2. How does SQL Server 2012 store data?
“SQL Server 2012 is a relational database that stores data in a row store. New features include columnar indexing, which indexes data in the row store with a columnar index.
“This allows queries to run very fast, making it comparable to dedicated columnar store databases like Vectorwise and Sybase IQ.”
3. How does Yellowfin connect to, and extract data from, SQL Server 2012?
“Like all relational database connections in Yellowfin, data is accessed via a JDBC driver.
“Yellowfin ships with the open source JTDS driver, but also supports the standard Microsoft JDBC connector.”
4. What were the challenges associated with integrating support for SQL Server 2012 in Yellowfin 6.1?
“Yellowfin has always supported SQL Server, and support for the new version was implicit, as SQL Server 2012 is syntactically compatible with previous releases.
“As part of our accreditation for SQL Server 2012, we had a SQL Server expert examine some of our connection methods, which highlighted issues with the cursor mode used by Yellowfin.
“Modifications to the cursor mode resulted in Yellowfin performance improvements when connecting to SQL Server 2012 and earlier releases.”
5. Under what circumstances would you suggest a customer move to SQL Server 2012, a relational database, over an analytical type of database?
“I would think that people looking to implement a data warehouse, that are already using SQL Server 2012 for a transactional system, will be less likely to deploy into a new analytical database, due to the new columnar features available in SQL Server 2012.”
6. How does a customer configure Yellowfin to use SQL Server 2012?
“Connecting to Yellowfin via SQL Server 2012 is just like any other JDBC source. Select Microsoft SQL Server from the database dropdown, and Yellowfin will prompt for all the required information.

“The only prerequisite for Yellowfin being able to connect to SQL Server 2012, is that it has the TCP/IP protocol enabled.”
Why total Big Data analytics solutions are needed – now!
To contextualize the need for total analytics packages, or partnerships, capable of handling the front-end and back-end demands of Big Data storage and exploration, “global digital content created will increase some 30 times over the next ten years – to 35 zettabytes”, according to IDC’s Digital Universe Study.

Gartner estimates that the total worldwide volume of data is growing at a rate of 59 percent per year. According to the international advisory and analyst goliath, Big Data – the continued proliferation of data, in combination with organizations’ desire to capture and analyze those mushrooming data volumes for deeper insight in continually shrinking timeframes – will drive $28 billion of worldwide IT spending in 2012.

To underpin the velocity aspect of the ‘3 Vs’ that encompass the term Big Data (Volume, Variety and Velocity), recent research by the Aberdeen Group, entitled Go big or Go Home? Maximizing the Value of Analytics and Big Data, found that the average organization leveraging Big Data via analytics “needed information on a business event within one day, but almost half (49%) reported needing actionable intelligence within the hour.” Aberdeen’s report defined organizations using Big Data as those with at least one analytic database larger than 1 terabyte (TB).

Gartner forecasts that Big Data will drive an incredible $34 billion in IT spending during 2013.
"Big Data represents an industry-wide market force which must be addressed in products, practices and solution delivery," said Mark Beyer, research vice president at Gartner in a recent media announcement. “By 2020, Big Data features and functionality will be non-differentiating and routinely expected from traditional enterprise vendors and part of their product offerings."
But, in the meantime, leveraging Big Data can provide a source of significant competitive advantage.
Research conducted by Professor Erik Brynjolfsson last year, and recently published in MIT Sloan Management Review, Harvard Business Review and the New York Times, suggested that those organizations adopting “data-driven decision-making” – by implementing Big Data analytics programs – experienced incredible productivity gains of five to six percent. Perhaps it’s no wonder that 83 percent of CIOs plan to increase organizational competitiveness via BI and analytics, according to IBM’s The Essential CIO study over 3,000 CIOs across 71 countries.
Harnessing the power of Big Data: BI for the people, by the people
And how do you achieve successful Big Data analytics deployments that deliver increased productivity and boost competitiveness? With consumer-oriented BI solutions and end-user driven BI deployments; that’s how.

According to two other studies conducted by the Aberdeen Group during 2012, organizations that have already deployed analytics projects aimed at exploring and leveraging Big Data for decision-making purposes are over 70 percent more likely, when compared to organizations that are inactive in their attempts to leverage Big Data, to have BI programs driven and utilized by business users (as opposed to the IT department). Aberdeen’s January 2012 survey on Big Data also defined organizations using Big Data as those with at least one analytic database larger than 1 TB. The same survey also revealed that those organizations already utilizing Big Data assets for analytics projects were 60% more likely to empower their business users to perform independent report building, manipulation and data analysis.
Similarly, Aberdeen’s April 2012 survey on Agile BI found that self-service reporting and analytics deployments were more pervasive within organizations actively using analytics to leverage Big Data. These findings suggest that end-user oriented BI solutions play an integral role in underpinning the successful exploration of Big Data – to further business objectives.
In fact, the same research found that 84 percent of organizations performing Big Data analytics – analyzing data stores over 1TB – were utilizing end-user oriented BI tools.
Give it to me straight, doc!
Essentially, Big Data – and Big Data analytics – should be approached and considered with this simple mentality: What’s the point of expending immense resources capturing and interrogating masses of information if the people that matter can’t access and explore that data to enhance their performance? Of what benefit is Big Data analytics if your business can’t take more efficient and effective action as a result?
Simply put; the age of Big Data only fortifies the focus on a long-held goal of reporting and analytics projects – to achieve pervasive self-service BI.
The latest release of Yellowfin’s Business Intelligence (BI) software (Yellowfin 6.1), had a large focus on equipping organizations with the support required to realize their Big Data analytics initiatives, offering support for a greater range of databases including D3, Connection Cloud, Lucid, Greenplum, Hadoop, SAP Hana, Vertica and SAS dataset connection.
Microsoft’s latest iteration of its relational database application, SQL Server 2012, did the same.
SQL Server 2012 incorporates a number of enhancements specifically designed to improve BI performance and stability for organizations analyzing Big Data. New additions include complete fault tolerance and disaster recovery with its ‘AlwaysOn’ feature, as well as significant performance improvements for analytics and data warehousing (of 10x – 100x) with its new ‘xVelocity’ in-memory technologies, which allows users to explore unprecedented amounts of data in real-time.

Microsoft’s whitepaper on SQL Server 2012, Solution Overview – Breakthrough Insight, also stated that the database provides support for “massive data warehousing”, with “enhanced features such as Remote Blob Storage and partitioned tables that scale to 15,000 partitions to support large sliding window scenarios.” Also available is “increased support for up to 256 logical cores to enable high-performance for very large workloads and consolidation scenarios. SQL Server 2012 also activates non-relational data types, bridging beyond the DataWarehouse to embrace Big Data through Hadoop.”
SQL Server 2012, like Yellowfin, enables Big Data exploration with native support for Hadoop – a free open-source Java-based framework from the Apache Software Foundation that supports the distribution and running of applications on clusters of servers with thousands of nodes and petabytes of data.
Find out more about how Yellowfin is addressing Big Data analytics with support for Hadoop HERE >

So, seeing as Yellowfin and SQL Server 2012 are aligned in their respective missions to enable organizations to explore and leverage their proliferating data sources, a partnership seemed only natural.
Check out the official media release, announcing Yellowfin’s formal support for Microsoft SQL Server 2012 HERE >

So, how exactly does Yellowfin 6.1 support SQL Server 2012 – the database codenamed ‘Denali’?
6 questions with chief Yellowfin product architect, Peter Damen
1. Ok, so what is SQL Server 2012?
“SQL Server, developed by Microsoft, is a relational database management system. Its chief function is to store and retrieve data as requested by other software applications. SQL Server 2012 is the latest iteration of Microsoft’s database application.
“There are around a dozen or more different editions of SQL Server 2012, aimed at catering for different workloads. Yellowfin is one of the first Australian ISVs to offer support for all editions of SQL Server 2012.”
2. How does SQL Server 2012 store data?
“SQL Server 2012 is a relational database that stores data in a row store. New features include columnar indexing, which indexes data in the row store with a columnar index.
“This allows queries to run very fast, making it comparable to dedicated columnar store databases like Vectorwise and Sybase IQ.”
3. How does Yellowfin connect to, and extract data from, SQL Server 2012?
“Like all relational database connections in Yellowfin, data is accessed via a JDBC driver.
“Yellowfin ships with the open source JTDS driver, but also supports the standard Microsoft JDBC connector.”
4. What were the challenges associated with integrating support for SQL Server 2012 in Yellowfin 6.1?
“Yellowfin has always supported SQL Server, and support for the new version was implicit, as SQL Server 2012 is syntactically compatible with previous releases.
“As part of our accreditation for SQL Server 2012, we had a SQL Server expert examine some of our connection methods, which highlighted issues with the cursor mode used by Yellowfin.
“Modifications to the cursor mode resulted in Yellowfin performance improvements when connecting to SQL Server 2012 and earlier releases.”
5. Under what circumstances would you suggest a customer move to SQL Server 2012, a relational database, over an analytical type of database?
“I would think that people looking to implement a data warehouse, that are already using SQL Server 2012 for a transactional system, will be less likely to deploy into a new analytical database, due to the new columnar features available in SQL Server 2012.”
6. How does a customer configure Yellowfin to use SQL Server 2012?
“Connecting to Yellowfin via SQL Server 2012 is just like any other JDBC source. Select Microsoft SQL Server from the database dropdown, and Yellowfin will prompt for all the required information.

“The only prerequisite for Yellowfin being able to connect to SQL Server 2012, is that it has the TCP/IP protocol enabled.”
Why total Big Data analytics solutions are needed – now!
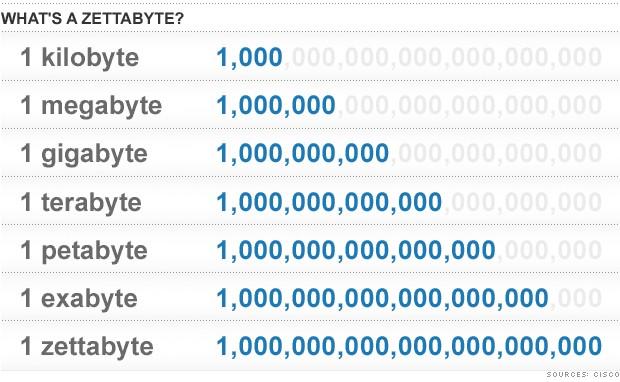
To contextualize the need for total analytics packages, or partnerships, capable of handling the front-end and back-end demands of Big Data storage and exploration, “global digital content created will increase some 30 times over the next ten years – to 35 zettabytes”, according to IDC’s Digital Universe Study.
Gartner estimates that the total worldwide volume of data is growing at a rate of 59 percent per year. According to the international advisory and analyst goliath, Big Data – the continued proliferation of data, in combination with organizations’ desire to capture and analyze those mushrooming data volumes for deeper insight in continually shrinking timeframes – will drive $28 billion of worldwide IT spending in 2012.

To underpin the velocity aspect of the ‘3 Vs’ that encompass the term Big Data (Volume, Variety and Velocity), recent research by the Aberdeen Group, entitled Go big or Go Home? Maximizing the Value of Analytics and Big Data, found that the average organization leveraging Big Data via analytics “needed information on a business event within one day, but almost half (49%) reported needing actionable intelligence within the hour.” Aberdeen’s report defined organizations using Big Data as those with at least one analytic database larger than 1 terabyte (TB).

Gartner forecasts that Big Data will drive an incredible $34 billion in IT spending during 2013.
"Big Data represents an industry-wide market force which must be addressed in products, practices and solution delivery," said Mark Beyer, research vice president at Gartner in a recent media announcement. “By 2020, Big Data features and functionality will be non-differentiating and routinely expected from traditional enterprise vendors and part of their product offerings."
But, in the meantime, leveraging Big Data can provide a source of significant competitive advantage.
Research conducted by Professor Erik Brynjolfsson last year, and recently published in MIT Sloan Management Review, Harvard Business Review and the New York Times, suggested that those organizations adopting “data-driven decision-making” – by implementing Big Data analytics programs – experienced incredible productivity gains of five to six percent. Perhaps it’s no wonder that 83 percent of CIOs plan to increase organizational competitiveness via BI and analytics, according to IBM’s The Essential CIO study over 3,000 CIOs across 71 countries.
Harnessing the power of Big Data: BI for the people, by the people
And how do you achieve successful Big Data analytics deployments that deliver increased productivity and boost competitiveness? With consumer-oriented BI solutions and end-user driven BI deployments; that’s how.

According to two other studies conducted by the Aberdeen Group during 2012, organizations that have already deployed analytics projects aimed at exploring and leveraging Big Data for decision-making purposes are over 70 percent more likely, when compared to organizations that are inactive in their attempts to leverage Big Data, to have BI programs driven and utilized by business users (as opposed to the IT department). Aberdeen’s January 2012 survey on Big Data also defined organizations using Big Data as those with at least one analytic database larger than 1 TB. The same survey also revealed that those organizations already utilizing Big Data assets for analytics projects were 60% more likely to empower their business users to perform independent report building, manipulation and data analysis.
Similarly, Aberdeen’s April 2012 survey on Agile BI found that self-service reporting and analytics deployments were more pervasive within organizations actively using analytics to leverage Big Data. These findings suggest that end-user oriented BI solutions play an integral role in underpinning the successful exploration of Big Data – to further business objectives.
In fact, the same research found that 84 percent of organizations performing Big Data analytics – analyzing data stores over 1TB – were utilizing end-user oriented BI tools.
Give it to me straight, doc!
Essentially, Big Data – and Big Data analytics – should be approached and considered with this simple mentality: What’s the point of expending immense resources capturing and interrogating masses of information if the people that matter can’t access and explore that data to enhance their performance? Of what benefit is Big Data analytics if your business can’t take more efficient and effective action as a result?

Simply put; the age of Big Data only fortifies the focus on a long-held goal of reporting and analytics projects – to achieve pervasive self-service BI.