
Yellowfin Evaluation Guide
Yellowfin is used for both enterprise analytics and embedded analytics use cases and for building bespoke analytical applications. Use this guide to ensure Yellowfin is the right technical fit for your requirements.

Architecture Overview
-
In this section
Updated 15 October 2024 -
Architecture Overview
What are the key components of Yellowfin Architecture
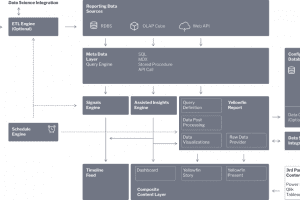
The following is a description of the key functional components of the Yellowfin architecture.
Configuration Database – stores all configuration data required by Yellowfin including information about users, security, data sources and content created in Yellowfin. Content created includes definitions of Reports, Charts, Dashboards, Presentations and Stories. Can be implemented in a variety of relational databases including SQLServer, MySQL and Oracle.
Reporting Data Sources – Yellowfin connects live to a wide variety of data sources including most popular relational and non-relational databases (with an appropriate jdbc driver), cubes (via MDX), flat files and API end-points (including out of the box connectors to popular cloud-applications). This framework is extensible, and Customers can create their own connections or use a third-party connection if one is available.
ETL Engine (optional) – this is an optional component that clients can utilise if they need to further transform their data to a form suitable for analytics. Data can be read from any source, combined, transformed and is then written back to any writeable DBMS that we support. A wide variety of transformation steps are available including merging data, splitting data, creating new columns, changing data types, replacing values and so on. In addition, Customers can connect an ETL work-flow to a third-party Data Science model to enhance data with the results of a predictive algorithm. We currently support models exported in pmml format, as well as live connections to R Servers, H20.ai and AWS SageMaker. The ETL step framework is extensible and Customers can build and plug-in their own custom-ETL steps.
Meta-data layer – this layer contains all of the necessary information about the data from which reports are to be built. This includes the table structures, join conditions, calculated fields, data formatting and so on. This data is then used by the Query Engine which generates DB specific queries in the form of SQL, MDX or other calls to dynamically query the live data connection. Data can also be sourced from a Stored Procedure or hand-coded SQL. Aspects of security are applied at this level including the application of access filters and/or data source substitution in order to support logical or physical segregation of data in a multi-tenant environment.
Yellowfin Report – this module is responsible for requesting data from the Query Engine, enhancing that data where necessary and generating the requested visualizations. Query Definitions contain the necessary detail of exactly which data is required to produce each report or visualization. There are various sub-engines which perform additional processing on the data once it is returned from the query engine:
- Post-processing Engine – this engine takes the raw data from a query and prepares it for presentation. This includes combining data from disparate data sources, performing cross-tabulation of data, converting data types, formatting data and also enriching data by performing complex post-processing. Post-processing can include the execution of advanced statistical calculations (such as percentage of total, StdDev, forecasts etc) and calling out to third-party applications to enrich data (such as invoking a predictive data-science model using the same framework as the ETL engine). Post processing functions are extensible, and clients can write and include their own functions to perform specific processing prior to data being displayed.
- Visualization Engine – this engine generates the visible content for users including Reports, Charts, Dashboards, Presentations and Stories. This framework is also extensible, for example Javascript charts can be included as well as other custom-built UI components.
- Raw Data Provider – the data sets returned from reports are accessible via API calls. Customers can perform custom processing on the underlying data sets prior to the data being presented in a Yellowfin visualization, or a custom UI element developed by the Customer.
- Data Cache – Yellowfin can be configured to cache data in order to speed up the end-user experience. A variety of data can be cached including actual report data, filter values, favourites and so on. Data refreshes can be scheduled via the Yellowfin scheduler.
Content Layer – Content can be consumed via the Yellowfin application from most popular browsers, from the native Yellowfin mobile App (IOS or Android) and individual components can be embedded into applications via API calls. Users will typically interact with Yellowfin Visualizations via a Dashboard, Presentation or Story – or a visualization embedded directly into a third-party application. The content layer can be reskinned and customized to meet the needs of the Customer. Other capabilities are available at the content layer including:-
- 3rd party content – commencing with the Story product, Customers can embed visualizations from third-party BI apps into Yellowfin. Content from Tableau, Qlik and PowerBI can be integrated and viewed alongside content from Yellowfin.
- Timeline Feed – the timeline feed serves personalised alerts and relevant content to users via the Yellowfin application, the mobile app or via a REST API.
Scheduling Engine – contains a flexible scheduling engine to schedule ETL jobs, Report distribution, Signals jobs and other system tasks. Some scheduled tasks can be triggered based for example on pre-defined thresholds being exceeded.
Signals Engine – the Signals engine automatically analyses data to identify data events of significance, and then generates personalized alerts that are delivered via the Timeline Feed, either in the browser client or mobile client. Signals jobs are configured in and leverage the meta-data layer and can be scheduled to run at any frequency using the Scheduling engine. The Signals engine is complex and contains a time-series generation engine, multiple event detection algorithms, a ranking and personalisation engine, and a notification engine.
Assisted Insights Engine – this is a set of algorithms that are invoked to automatically generate data insights on the fly. These insights are accessible through direct user interaction with a chart visualisation, through the report builder process and also to provide deeper explanations behind Signals.
-
Technical Architecture
What are the key components of the Yellowfin platform architecture?
Yellowfin consists of a Java Application Server (that runs on Apache Tomcat), and Repository Database. The Repository Database can exist on one of the following supported database systems: PostgreSQL, Microsoft SQL Server, MySQL, Oracle, DB2 or Ingres.
The application can be scaled for greater capacity and failover by clustering multiple Yellowfin Application Servers against the same repository database.
Application Server
What application server can I use to run Yellowfin?
Yellowfin will install an instance of Tomcat during installation. Clients that wish to use a third-party Java Application Server can consume Yellowfin as a WAR file, for deployment on their existing infrastructure.
Tomcat has several connectors that enable integration with external Web Servers to allow Yellowfin to be exposed on an existing website or portal. This includes Apache, IIS and Nginx.
Are there any external proprietary components or libraries shipped with Yellowfin?
No proprietary libraries are shipped with Yellowfin.
What open source libraries are shipped with Yellowfin?
Yellowfin ships with many permissibly licenced open-source libraries. A full list of these is documented in the legal directory of the Yellowfin installation.
Does my reporting data ever come to rest in Yellowfin?
Yellowfin will store data in memory temporarily whilst reports and dashboards are being viewed. Other options, which are not enabled by default, allow reports and filter values to be cached in the Repository Database. This is used for taking a snapshot of a report, and for allowing users to choose filter values from a dropdown list. The Report Data Cache can also store data in memory. This will store the dataset of a Report Query for reuse within a configurable time period.
Repository Database
Where is my configuration data stored?
All configuration data and meta-data, including users, groups, and content definitions are stored in the Repository Database in a relational schema. This database is created on installation and can exist in one of the following supported database systems: PostgreSQL, Microsoft SQL Server, MySQL, Oracle, DB2 or Ingres.
How do I back up my configuration data?
A complete backup of Yellowfin’s configuration can be taken by backing up the repository database. Backups can be used for periodic snapshots, or for moving or cloning environments between systems. Using database functionality, like Log Shipping, or clustering allows configuration data to be backed up in realtime, and provide failover and disaster recovery.
-
Openness & Extensibility
Deploy anywhere
What operating systems can I deploy into?
Yellowfin can be installed on Windows, Linux or Mac OSX based desktop or laptop for evaluation or training purposes and installed on Windows, Linux or Mac OSX based servers for evaluation, training and production purposes.
What cloud environments can I deploy into?
Yellowfin will work with all of the major cloud providers including AWS, Azure, GCP and more.
Can I run Yellowfin instances on premise?
Yes, you can deploy on-premise or in the cloud.
No Vendor Lock-in
Can I avoid being locked into the Yellowfin platform?
ESCROW – grants you access to the source code of the platform in the event of insolvency on the part of Yellowfin
Access to your content design and code extensions (which you own) — even if you stop using Yellowfin, you can use the rich visual content and code extensions of your apps and dashboards towards re-engineering in another platform or technology
Your data can be stored inside any database of your choice — this is owned and accessible by you at all timesWill I be locked into a Proprietary Database
No, Yellowfin does not have its own proprietary database or in-memory database. All data is stored in commonly used database management systems of your choice.
As a result you can access your data at all times and use it with other tools, or move your data into any other DBMS of your choice.Will I need to learn a Proprietary Scripting Language
No, Yellowfin has no proprietary scripting languages to either move data or build visualizations, uses. Yellowfin only uses common industry languages or drag and drop functionality for all of its processes. For example, to create a Yellowfin metadata layer you can use drag and drop GUI or SQL, or for Code mode on dashboards use HTML, JavaScript and CSS.
Can I choose to host Yellowfin in any environment?
With Yellowfin you can deploy on premise, in your own data center or on the cloud provider of your choice such as AWS, Azure, Google, Oracle etc
Can I use my existing data warehouse environment?
Yes, Yellowfin connects to many DBMS and does not ingest data into a proprietary format. So if your data is already prepared and in a format that is optimised for reporting you will not have to move it or do any further work on your data. Simply connect to your data warehouse and start building content.
Exposed API’s
What kind of APIs does Yellowfin expose?
Yellowfin has two main API capabilities:
The JavaScript API – used for embedding report and dashboard content in a third party application
Web Services API – a rich variety of services used for automating administrative tasks, programmatically manipulating content such as users, security permissions of meta-data, or for integrating content into an application (web application or mobile app). Both SOAP and REST web services are supported.Can I automate Yellowfin processes?
Yes a variety of administrative processes can be automated using the Web Services layer.
Can I create data models in Yellowfin automatically based on my schema?
Yes – the meta-data model can be directly manipulated using Web Services, or content files can be built externally to the agreed standard and imported into Yellowfin using the Import web service.
Extensibility
How can I extend the functionality of Yellowfin?
Yellowfin offers a variety of ways to extend our functionality. You can create custom workflows and user experiences, add extensions through our plug-in componentry and more. For a full range of what’s possible see extending Yellowfin